
Abstract
Connector-based video unified models have demonstrated strong capability in instruction-grounded video synthesis, but integrating a large high-fidelity generator into the unified training loop is computationally prohibitive, limiting achievable visual quality. We therefore propose Lumos-Nexus, a training-efficient unified video generation framework that facilitates the development of strong reasoning-driven generation capabilities while significantly enhancing visual fidelity. Lumos-Nexus adopts a two-stage design: 1) During training, only a lightweight generator is aligned with the understanding block to learn to take in reasoning-driven semantic control. 2) During inference, we introduce Unified Progressive Frequency Bridging (UPFB) to progressively hand off generation to a high-capacity pretrained generator in the shared latent space, enabling coarse-to-fine refinement and producing high-fidelity videos without compromising reasoning quality. To fill the gap in reasoning-driven video generation benchmarks, we introduce VR-Bench, which assesses a model's capability to translate inferred intent into coherent and semantically aligned video content. Extensive experiments demonstrate that Lumos-Nexus achieves substantial gains in visual realism and temporal coherence on VBench, while exhibiting strong reasoning-based generative performance on VR-Bench.
Method Pipeline
Overview of Lumos-Nexus. (a): The connector and small generator are fine-tuned within the connector-based video unified model during training. (b): inference performs Unified Progressive Frequency Bridging (UPFB) to combine the small generator's semantic guidance with high-fidelity details from the large generator for high-quality video generation.
VR-Bench
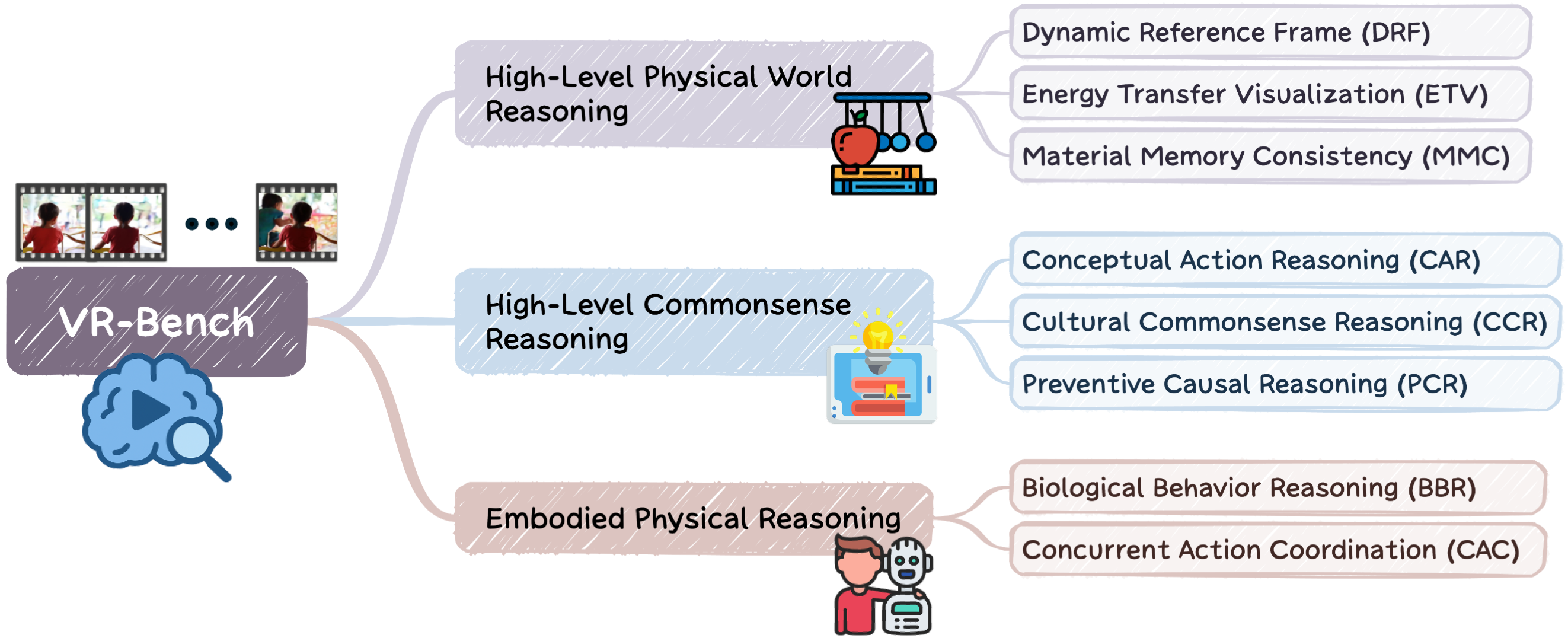
VR-Bench covers three hierarchical categories: (1) High-Level Physical World Reasoning, capturing physical dynamics and material interactions; (2) High-Level Commonsense Reasoning, assessing causal, cultural, and abstract behavioral understanding; and (3) Embodied Physical Reasoning, focusing on motion coherence and grounded physical interactions.
Embodied Physical Reasoning

Wan2.1-1.3B
Wan2.1-14B
Omni-Video
Lumos-Nexus

Wan2.1-1.3B
Wan2.1-14B
Omni-Video
Lumos-Nexus
High-Level Commonsense Reasoning

Wan2.1-1.3B
Wan2.1-14B
Omni-Video
Lumos-Nexus

Wan2.1-1.3B
Wan2.1-14B
Omni-Video
Lumos-Nexus

Wan2.1-1.3B
Wan2.1-14B
Omni-Video
Lumos-Nexus
High-Level Physical World Reasoning

Wan2.1-1.3B
Wan2.1-14B
Omni-Video
Lumos-Nexus

Wan2.1-1.3B
Wan2.1-14B
Omni-Video
Lumos-Nexus

Wan2.1-1.3B
Wan2.1-14B
Omni-Video
Lumos-Nexus
More Visualizations
BibTeX
@misc{xing2026lumosnexusefficientfrequencybridging,
title={Lumos-Nexus: Efficient Frequency Bridging with Homogeneous Latent Space for Video Unified Models},
author={Jiazheng Xing and Hangjie Yuan and Lingling Cai and Xinyu Liu and Yujie Wei and Fei Du and Hai Ci and Tao Feng and Jiasheng Tang and Weihua Chen and Fan Wang and Yong Liu},
year={2026},
eprint={2605.31603},
archivePrefix={arXiv},
primaryClass={cs.CV}
}